Abstract
We explore the intersection of two distinct research areas: conditional image-to-video generation and music-to-dance generation. We introduce a novel approach that directly generates dance videos from a single image and accompanying music. This research not only investigates the role of music as a conditional input in image-to-video synthesis but also sets a foundational benchmark for direct dance video generation in response to musical cues. We further examine the extraction of crucial information for enhancing motion-music beat alignment, leveraging both a large-scale foundational model and established signal-processing tool. Through extensive experimentation, we have established a robust baseline for this novel task.
Method
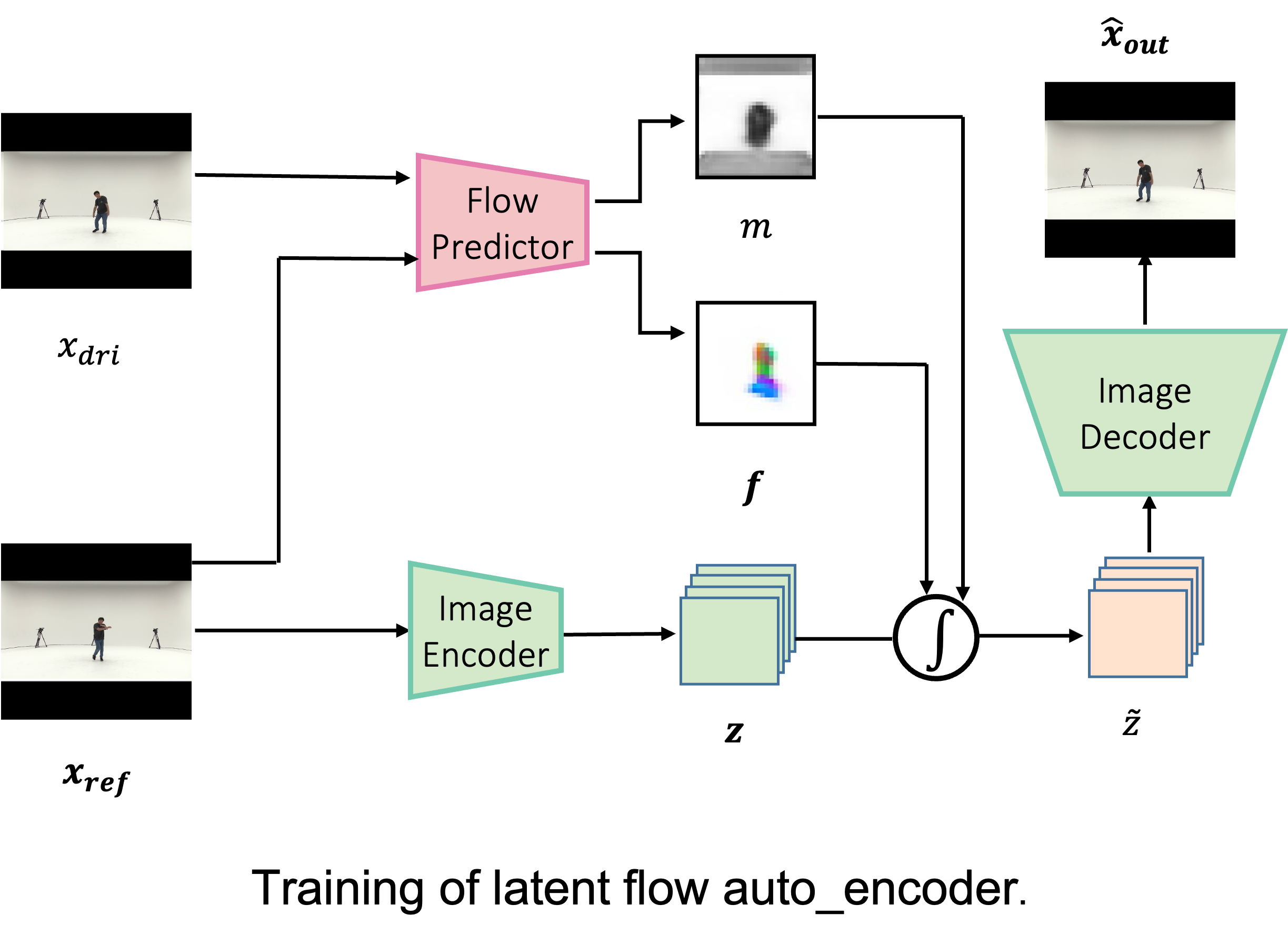
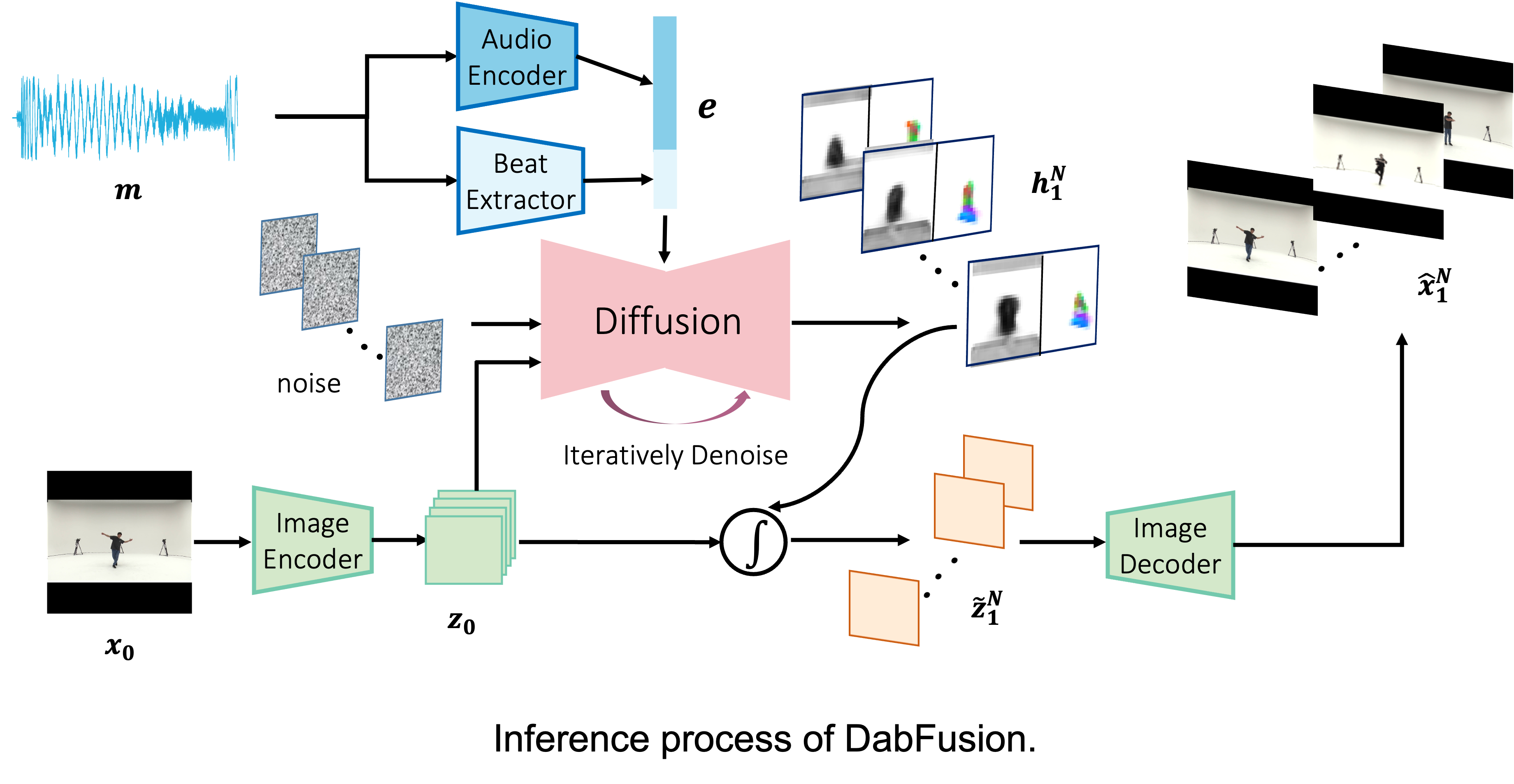
The aim of our methodology is to generate latent optical flows guided by musical inputs. Recent works in motion transfer have demonstrated the efficacy of employing latent optical flow for warping one image into another. Additionally, the generation process becomes more resource-efficient when operating in a low-dimensional latent flow space, which requires less computational power and time compared to working within high-dimensional pixel or latent feature spaces. In selecting a model for generation, the exceptional quality and robust controllability afforded by diffusion models make them an ideal choice. The initial phase of our methodology involves training an auto-encoder to discern the optical flow between two frames within a video sequence. Subsequently, this trained auto-encoder aids in the training of the diffusion model, enabling the generation of latent flows. Another fundamental aspect of our approach is the extraction of musical information. For our baseline model, we employ CLAP to encode the music, while our enhanced model additionally incorporates beat information for a better representation.




